Uno de los errores más comunes que cometemos los desarrolladores es creer que un patrón de diseño va a solucionar todos nuestros problemas. A lo largo de mi carrera he utilizado (bien y mal) varios lenguajes y frameworks lo cual me ha permitido digamos tomar las mejores ideas de cada uno y por otra parte, tratar de no arrastrar las malas prácticas.
Introducción
Diría que tengo poco tiempo usando ruby, sin embargo, en tiempos tecnológicos, 4 años es suficiente. Suficiente al menos para generar un juicio basado en experiencia. Una de las cosas que es obvia cuando uno llega a la comunidad de programadores de ruby es la herramienta que hizo popular a este lenguaje: ruby on rails, o simplemente rails. Rails fue uno de los precursores (junto con django y codeigniter probablemente) de los frameworks para desarrollo web ágil, es decir aquellos que proponían un patrón de diseño para organizar el software llamado MVC lo cual hasta el día de hoy, sigue siendo válido, sin embargo, algo que hacía particular a rails era su filosfía de «convenciones sobre configuraciones» es decir, dejar al framework decidir ciertas cosas de manera que podamos enfocarnos en solucionar el problema que tratamos de solucionar aplicando el software y evitar así invertir tiempo en diseñar un software para diseñar otro. ¿Muy buena idea, no?
MVC NO es una arquitectura
Algo peculiar de la comunidad de programadores de ruby es que muchos llegaron con daño post-traumático de otras tecnologías; venir de programar de PHP por ejemplo tiene sus secuelas, así que al encontrar pastos más verdes en ruby y en especial en rails, es natural que a veces se tomen las recomendaciones de nuestro nuevo lenguaje o framework favorito casi como dogma. Uno de esos dogmas es precisamente MVC. Leer las guías oficiales y tutoriales usualmente nos deja satisfechos y creemos que vamos por un buen camino sin embargo, cuando nos topamos con aplicaciones más complejas parece que estas convenciones comienzan a quedarse cortas y no hay nada en las guías oficiales sobre como diseñar algo más allá que el «blog de 15 minutos«.
El problema no es el patrón MVC en sí, el problema es querer solucionar la arquitectura de nuestra aplicación con un patrón de diseño. En varias ocasiones he tenido esta discusión con colegas para tratar de explicarles que aunque MVC es un patrón de diseño o estructura de proyecto no es una arquitectura, es decir, aun cuando optamos por usar este patrón debemos de conceptualizar una arquitectura para ella donde todo tenga sentido.
Pero escuchenlo de alguien con más autoridad, Uncle Bob, programador desde los 70’s y creador del Agile Manifesto:
Les recomiendo que vean el video completo, cuando tengan tiempo. Tiene excelente información y ahonda en el tema de diseño de software que por obvias razones no haré en esta publicación.
De hecho el tío Bob hace una buena analogía sobre arquitectura poniendo como ejemplo una iglesia. Si pensamos desde la perspectiva de arte, la arquitectura es la práctica de diseñar espacios habitables, monumentos, estructuras urbanas, etc. Yo particularmente, como el tío Bob, he encontrado esta analogía de mucha ayuda para explicar el concepto de arquitectura de software y en realidad no es porque lo vi en el video sino que estoy rodeado de gente que se dedica al tema; desde mi esposa que es arquitecta pasando por primos ingenieros civiles, mi padre, mi suegro. Mucha gente a mi alrededor se dedica al tema de «la construcción» así que digamos estoy un poco empapado en el tema.
Por ejemplo y para poner un poco de contexto: cuando se construye un edificio este podría tener un diseño que siga cierta corriente; Art Deco, Barroco, Gótico, Minimalista. Cada uno de estos estilos tiene su propia personalidad y lineamientos para que una construcción u obra arquitectónica sea considerada de tal estilo, sin embargo, pueden existir decenas de edificios de estilo barroco, por ejemplo, y que sean totalmente diferentes. Uno puede tener 8 pisos, otro puede tener 20, uno puede hacer uso de 2 elevadores mientras que el otro quizá tenga 4 en servicio y dado que uno es mas alto que el otro probablemente los cimientos del segundo sean más profundos o de mayor grosor.
Podemos pensar que MVC entonces es un estilo arquitectónico, más no es toda la arquitectura. Tomando el ejemplo anterior se deduce que cada proyecto de construcción tiene requerimientos diferentes y por lo tanto una arquitectura diferente, es decir, cada una de estas obras tiene planos de construcción que seguramente no se parecen en nada, cada arquitecto e ingeniero civil abordará los problemas de manera diferente buscando una solución a esa obra en particular ¿Por qué no haríamos lo mismo con el software?
«Fat controllers» y «God objects»
¿Cómo identificar si nuestra arquitectura es la correcta? Bueno, la verdad es que para mi no existe tal cosa. Como ya lo dije en el párrafo anterior: cada proyecto tiene necesidades y requerimientos diferentes y por lo tanto podemos deducir que cada proyecto deberá tener un diseño único, sin embargo hay algunos «anti-patrones» que podemos detectar cuando utilizamos ruby on rails (o en realidad, cualquier otro framework MVC) y que son indicadores comunes de un mal diseño de software:
- Controladores con demasiado código (fat controllers)
- Modelos con demasiado código (fat models)
- Clases que hacen demasiadas cosas (god objects)
Aunque existen más indicadores de «smelly code» que los expuestos arriba, estos usualmente son los principales en cualquier framework MVC y sobre todo en rails. Pero entonces ¿Cómo diseñamos nuestras aplicaciones de manera que coexista con el patrón de diseño MVC?
Antes de sugerir una solución hay que entender el problema, y la manera que he utilizado por varios años de explicarlo es con un plano cartesiano, ¿Lo recuerdan de sus clases de matemáticas, cierto? Bien. Tomemos entonces la siguiente gráfica:

En nuestro eje X tenemos el patrón de diseño MVC. En una aplicación MVC usualmente se sigue un estándar para delegar responsabilidades a cada capa donde usualmente:
- La vista se encarga de procesar salida de datos al usuario o cliente que consume la aplicación
- El controlador se encarga de procesar la entrada de datos del usuario o peticiones y generar salida hacia la vista
- El modelo se encarga de encapsular las entidades de datos de una fuente como bases de datos relacionales (SQL) o no relacionales (mongo)
Y ahí es precisamente donde queda la duda de donde acomodar nuestro código. Tomemos un caso de uso bastante simple. Nuestro requerimiento sería crear un usuario con los datos provistos y guardarlo en la base de datos, sin embargo, tenemos otro requerimiento extra: antes de crear el usuario debemos generar un token de usuario que proviene de un sistema externo, y una vez que el usuario ha sido creado satisfactoriamente con ese token asignado que proviene de un sistema del cual no tenemos control, debemos enviar un correo de bienvenida.
Lo natural sería tener algo parecido a esto en nuestro controlador:
Y después nuestro modelo:
Por obvias razones simplifiqué el código pero se entiende el punto. Ahora tenemos que cumplir los otros requerimientos; obtener un token que viene de un sistema externo y enviar el correo al usuario. Acto seguido hacemos lo siguiente en nuestro modelo:
Se agregó un callback para antes de crear al usuario que obtiene el token de un servidor externo y otro callback para después de creado el usuario enviarle un correo de bienvenida. Este tipo de patrones es muy común verlos en tutoriales para principiantes o incluso en guías oficiales. Aunque los callbacks tienen su razón de ser, en este caso en particular, se hace mal uso de ellos, y aquí listo algunos ejemplos:
- ¿Qué pasa si hay un timeout en la respuesta del servicio externo, o algún otro tipo de error?
- ¿Qué pasa si hay una excepción en el flujo de la aplicación donde deseamos crear un usuario manualmente (por ejemplo por medio de un panel de administración) y no deseamos enviar el correo?
- Para el caso del punto 2 ¿Que tal si deseamos proveer desde el admin un token manualmente y solo se genera si no existe uno?
Es entonces cuando usualmente empezamos a abusar del modelo y comenzar a condicionar los callbacks, agregar código de validaciones de reglas de negocio, etc. Rails lo hace bastante fácil, y ese es el problema. Una vez que seguimos este patrón de estar administrando el flujo de la aplicación en los modelos con cientos de líneas de código que nada tienen que ver con la lectura o almacenamiento de datos sino de como interactuan como el usuario es que convertirmos un modelo en un «fat model«.
Nuestra lógica nos dirá «Bien, si no debemos condicionar el modelo a reglas de negocio entonces parametricemos el controlador de manera que podamos indicar si deseamos asignar manualmente el token y si debemos enviar correo de bienvenida al usuario o no» y entonces hacemos esto:
Aunque solucionamos el «problema» de la parametrización solo movimos el otro problema; convertimos ahora el controlador en un «fat controller«, es decir, el controlador contiene código condicional de reglas de negocio. Recordemos que el controlador solo debería de encargarse de administrar la entrada de datos y peticiones y formatear la salida o respuesta hacia la vista. El siguiente intento común es encapsular dicho código y meterlo en un helper:
Acto seguido incluimos dicho helper en nuestro controlador y lo integramos:
Pero seguimos teniendo algunos problemas con el controlador:
- Código condicional para el flujo de reglas de negocio
- Solo volvimos a mover el problema de lugar
Rayos! Esto se vuelve cada vez más complicado. Resulta que al mover nuestros métodos al módulo que estamos incluyendo estamos creando lo que se conoce como un «god object«, es decir, un módulo o clase que contiene demasiada funcionalidad. Aunque en nuestro ejemplo el código es muy básico y simple con un par de métodos, no es raro ver estos helpers o clases contener decenas o centenas de métodos para hacer prácticamente cualquier cosa relacionada a un usuario. Mantener ese tipo de código se vuelve muy complicado. De wikipedia:
In object-oriented programming, a God object is an object that knows too much or does too much. The God object is an example of an anti-pattern.
A common programming technique is to separate a large problem into several smaller problems (a divide and conquer strategy) and create solutions for each of them. Once the smaller problems are solved, the big problem as a whole has been solved. Therefore a given object for a small problem need only know about itself. Likewise, there is only one set of problems an object needs to solve: its own problems.
Y considerando que utilizamos ruby, un lenguaje orientado a objetos, estamos rompiendo una de las reglas y creando un anti-patrón.
Service Objects
Dado que ahora entendemos el problema con los anti-patrones más comunes puedo presentar la solución: servicios, o service objects, pero ¿Qué son estos servicios? Bueno, son pequeñas clases que encapsulan funcionalidad relacionada a la misma operación y que usamos para concretar una transacción u operación donde todos los pasos están conectados y son relevantes de alguna manera. Pero antes de ver como diseñarlos me gustaría discutir donde ponerlos.
Recordemos nuestro gráfico con el plano cartesiano. El eje de la X contiene todo el patrón de diseño MVC, el problema que tratamos de solucionar es donde meter nuestro código que no tiene que ver con controladores, vistas o modelos. La respuesta es simple: en ningún lugar, o mejor dicho, en ningún lugar del eje X. Suena complicado, lo se, pero diseñe algunas otras imágenes para explicarlo mejor:
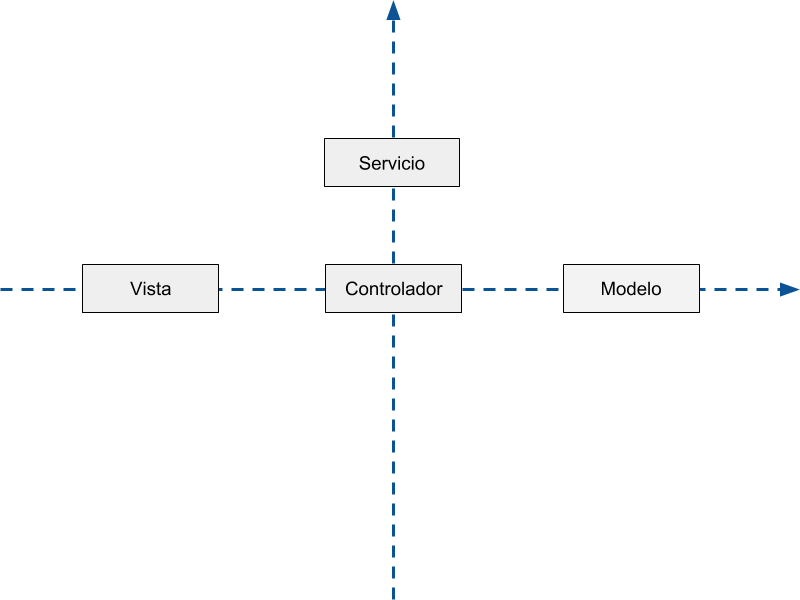
Como vemos en la imagen anterior se agregó otro recuadro llamado Servicio. El punto importante aquí es entender que todo ese código cuya responsabilidad no sea administrar peticiones o respuestas, formatear salida de información o interactuar con nuestras entidades de datos no pertenecen al eje X, es decir, no son parte del ciclo de MVC, sin embargo, ese código en algún lugar debe vivir y es precisamente por esa razón que uso el plano de ejemplo, este código reside en el eje Y, es decir, no está paralelo al código del patrón MVC.
Incluso podemos ir más allá utilizando nuestro mismo ejemplo de creación de usuarios. Sabemos por ejemplo crear un usuario involucra además del envío del correo, que es algo que ya nos provee rails, generar un token posiblemente de un sistema externo. Esto suena como algo que deberíamos de hacer en una librería de hecho y no en el servicio, es decir, podríamos tener otra capa que se encargue de estas operaciones de más bajo nivel por decirlo de alguna manera, tal como en el eje X usamos el patrón de MVC donde cada parte tiene una responsabilidad:

Una vez que tenemos diseñada nuestra arquitectura inicial la siguiente pregunta, probablemente, es ¿Cuándo se intersectan estas partes, y donde? Bueno, eso depende de varios factores pero lo natural sería pensar que al nivel del controlador, como lo muestra la imagen anterior, sin embargo, suponiendo que nuestro servicio debe asignar el token generado externamente al usuario esto significa que el servicio también debe poder tener acceso al modelo. En resumen, nuestro servicio debe:
- Recibir un opciones de parametrización (parte del request, concern del controlador)
- Recibir un objeto de tipo usuario (como entidad de datos, parte del modelo)
- Retornar una respuesta para que el controlador pueda hacer algo con ella
Entonces podemos deducir de lo anterior que el servicio de hecho debe poder interactuar tanto con el controlador como con el modelo. Nuestro diseño de arquitectura entonces nos dice que la intersección de ambas cosas de hecho no es en el centro sino en otro punto intermedio de manera que todos los elementos puedan interactuar pero a la vez ser independientes:

En este caso tenemos en la imagen los siguientes puntos con el flujo:
- El controlador recibe una petición con parámetros, construye un usuario y pasa ambas cosas al servicio, recibe una respuesta del servicio y actúa de acuerdo a dicha respuesta
- El servicio recibe los parámetros y el objeto del usuario, manda llamar a la librería que consume el servicio externo y genera un token si es necesario
- El servicio asigna al atributo token del modelo el valor que la librería retornó o bien aquel que viene en los parámetros, según el caso.
Una vez entendidos los conceptos anteriores es fácil implementar servicios y saber donde va cada cosa. Ahora, el siguiente paso es inspeccionar el diseño del servicio en si. Existen muchos patrones de diseño para crear servicios y cada uno tiene sus ventajas y desventajas. Conforme fui adquiriendo experiencia y basado sobre todo en casos de uso he diseñado mi «estandar de servicio» de la siguiente manera:
- Un servicio debe hacer una sola cosa y hacerla bien
- Un servicio debe poder recibir entrada de datos para procesarla
- Un servicio debe poder retornar salida de datos ya procesada
- Un servicio debe indicar estatus de la operación
- Un servicio debe proveer mensajes de errores y/o depuración
Lo anterior más que una cosa personal es simplemente inspiración. ¿Han escuchado hablar de la filosofía de UNIX?
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
Esta filosofía de diseño es lo que ha permitido a los sistemas UNIX como Linux y BSD seguir vigentes casi por 40 años. La mayoría de estas aplicaciones pequeñas como grep, awk, sed, ls, cat, etc. hacen una sola cosa y la hacen bien, pero no solo eso, siguen este patrón de entrada de datos <-> salida de datos y código de retorno. Entonces, si esto ha funcionado por tanto tiempo ¿Por qué tratar de reinventar la rueda? Pensemos entonces en nuestros servicios como pequeñas aplicaciones unix donde nuestro sistema operativo es toda nuestra aplicación.
Siguiendo la filosofía explicada anteriormente hay otras reglas que aplico a los servicios particularmente:
- El nombre del servicio debe indicar exactamente lo que hace
- El servicio solo debe contener un método público perform que ejecuta la operación
- El método perform retorna true si la operación fue exitosa o false de lo contrario
- El servicio expone un atributo output donde puede haber salida de datos si es necesario que retorne algo
- El servicio expone un atributo errors que contiene un array de mensajes de error si el servició falló
- El servicio expone un atributo messages que contiene un array de mensajes de depuración o informativos independientemente del estatus exitoso o no
- Todos los datos necesarios para procesar el servicio se reciben en el inicializador
Entonces regresando a nuestro caso de la creación de usuarios tenemos como tarea por una parte encapsular la funcionalidad externa para obtener un token en una librería, crear un servicio usando nuestro estándar que se encargaría de llamar esta librería y enviar o no el correo de bienvenida y finalmente integrar todo esto a nuestra aplicación de rails.
Nuestra librería quedaría así:
Nuestro servicio:
Y finalmente la implementación en nuestro controlador:
Como vemos el código del controlador está excepcionalmente limpio, y de hecho si quisieramos aplicar ciertas reglas para cada acción del CRUD, por ejemplo cuando actualizamos, o eliminamos, podríamos seguir el mismo patrón, encapsulando esas reglas de negocio en servicios y mandándolos llamar en el controlador y aun así sería muy legible y entendible:
Solo como convención adicional, para que esto funcione debemos meter nuestras librerías y servicios siguiendo las convenciones de rails, por ejemplo:
lib/token_provider.rb
app/services/create_user_service.rb
Y asegurarnos que tenemos configurados estos directorios en autoload:
config.autoload_paths += Dir[Rails.root.join('lib')] config.autoload_paths += Dir[Rails.root.join('app/services')]
Con estas líneas en nuestro application.rb nos aseguramos que estas clases serán autocargadas y así evitar que tener que hacer require.
Conclusión
Aunque existen muchos patrones de diseño de software creo que ninguno se ajustará a nuestras necesidades al 100% y es ahí donde entra la arquitectura de software, esa que finalmente diseñamos nosotros, basados en los propios requerimientos. He utilizado este approach particularmente en ruby on rails en varios proyectos (en producción, mantenibles, usados por clientes) y hasta el día de hoy el resultado ha sido bueno. Incluso para otros frameworks en otros lenguajes orientados a objetos puede ser una buena alternativa para dividir responsabilidades de nuestros objetos y mantener una buena base de código mantenible y extensible.
Al final del día, lo que es importante recalcar es que debemos tomar las buenas partes de un patrón de diseño, framework o metodología de trabajo y aplicarlo a nuestras necesidades y cuando no se ajuste al 100% pensar como arquitectos donde cada proyecto de software, al igual que cada casa, edificio o puente, tiene planos diferentes, basados en técnicas parecidas, si, pero finalmente con ideas propias.
Leído, que bien documentado quedó! Muchas felicidades creo que mejor usaré tu post para poder referirme al propósito de cada pedazo de código y procurar explicarles a los morros el cómo identificar y proponer el futuro de la intención de una pieza de código, segun su funcion!